Welcome to Constant Etherpad!
These pads are archived each night (around 4AM CET) @
http://etherdump.constantvzw.org/
An RSS feed from the etherdump also appears on
http://constantvzw.org/
To prevent your public pad from appearing in the archive and RSS feed, put or just leave the following (including the surrounding double underscores) anywhere in the text of your pad:
__NOPUBLISH__
Changes will be reflected after the next update at 4AM.
Algorithmic Uncertainty
pad paradise
-------------------------------------------------------------------------------------------------------------------------------------------
Algemene pad:
http://pad.constantvzw.org/p/algorithmic_uncertainty
Afspraken met Mike:
http://osp.kitchen:9999/p/algorithmic_uncertainty
Visualisaties:
http://pad.constantvzw.org/p/algorithmic_uncertainty_viz
Blog manual:
http://pad.constantvzw.org/p/algorithmic_uncertainty_blog
Extra City workshop Antwerpen:
http://pad.constantvzw.org/p/algorithmic_uncertainty.extracity
Op zoek naar een model:
http://pad.constantvzw.org/p/algorithmic_uncertainty.modellen
Nederlandse media aandacht:
http://pad.constantvzw.org/p/algorithmic_uncertainty.media
Vragen:
http://pad.constantvzw.org/p/algorithmic_uncertainty.questions
-------------------------------------------------------------------------------------------------------------------------------------------
op zoek naar een model
academische opties
-
Evaluation of named entity recognition in user-submitted police reports, Marijn Schraagen and Floris Bex – Utrecht University
-
zie:
http://www.ccl.kuleuven.be/CLIN27/abstracts.html#__RefHeading__3309_416941155
-
The website of the Dutch Police facilitates submitting a crime report, partly consisting of free text. To automate report processing, relation extraction can be used, which in turn requires accurate named entity recognition (NER). However, NER as offered by current Dutch parsers suffers from limited accuracy. Issues with grammaticality and spelling of the crime reports impair the NER even further. The current research aims to evaluate NER results on the crime reports data set using large-scale human judgment. The experiments are in progress, and the first results have been collected. Aspects of this evaluation include assignment of named entity types, recognition of multiword entities, mixed language issues and theoretical considerations on the nature and use of named entities. The evaluation is intended to provide pointers for increasing NER accuracy on this type of data.
-
Keywords: named entity recognition – evaluation – spelling errors – free text entry – crime reports
-
-
Generative Adversarial Networks for Dialogue Generation
-
Elia Bruni and Raquel Fernández – University of Amsterdam
-
Despite the great success of artificial neural networks in modelling a variety of language tasks, they are still very dependent on human supervision. The consequence is that the learning has to be static and passive, where the kind of training data is fixed once and for all. On the other hand, human communication is a dynamic process which proceeds by an active and incremental update of the speakers’ knowledge state. If we had to train an artificial agent to successfully communicate by supervision, the machine and the human would have to engage in an almost infinite loop in which, at each significant learning progress of the agent, a new round of more sophisticated human annotations should follow. Here we present a learning framework that tries to address this limitation. The core of our proposal is to let computational agents co-exist in the same environment and teach each other language with minimal need for external supervision. In particular, we adapt the recently introduced Generative Adversarial Networks (GAN) framework to the case of dialogue. The idea behind GAN is to re-frame the learning problem as a game played by two artificial agents locked in a battle: a discriminator trying to distinguish real data from fake data and a generator network trying to fool the discriminator by creating data that are indistinguishable from real data. In our case the type of data are dialogue passages, so that the generator has to fool the discriminator by producing human plausible dialogue turns. Keywords: Dialogue Generation – GAN – Deep Learning – Reinforcement Learning
-
-
What do Neural Networks need in order to generalize? Raquel G. Alhama and Willem Zuidema – University of Amsterdam
-
In an influential paper, reporting on a combination of artificial language learning experiments with babies, computational simulations and philosophical arguments, Marcus et al. (1999) claimed that connectionist models cannot account for human success at learning tasks that involved generalization of abstract knowledge such as grammatical rules. This claim triggered a heated debate, centered mostly around variants of the Simple Recurrent Network model (Elman, 1990). In our work, we revisit this unresolved debate and analyze the underlying issues from a different perspective. We argue that, in order to simulate human-like learning of grammatical rules, a neural network model should not be used as a tabula rasa, but rather, the initial wiring of the neural connections and the experience acquired prior to the actual task should be incorporated into the model. We present two methods that aim to provide such initial state: a manipulation of the initial connections of the network in a cognitively plausible manner (concretely, by implementing a “delay-line” memory), and a pre-training algorithm that incrementally challenges the network with novel stimuli. We implement such techniques in an Echo State Network (Jaeger, 2001), and we show that only when combining both techniques the ESN is able to succeed at the grammar discrimination task suggested by Marcus et al. Keywords: artificial language learning – rule learning – neural-symbolic computation – neural networks
-
Conceptual Change, UvA CREATE onderzoeksgroep, onderzoek rondom de geschiedenis van het woord 'democratie' in het parlement en de media
http://www.create.humanities.uva.nl/text-mining/
-
An oft-repeated objection against text-mining is that “words are not ideas”. The last couple of years, however, a stream of literature demonstrated how distributional semantics can offer efficient representations of word meaning, maybe even provide a model for tracking ideas over time. Moreover, these models can computationally identify semantic shifts over time. This project investigates how distributional semantics ties in with “Begriffsgeschichte”, i.e. how computational models of meaning align with interpretations based on close reading. As a case study, we focus on the history of “democracy” in parliamentary and media discourse. The case should establish the best practices, and define the benefits and limitations of a computational “Begriffsgeschichte”.
-
-
"Semantics derived automatically from language corpora necessarily contain human biases", Princeton University + University of Bath
https://arxiv.org/abs/1608.07187
-
definitieve versie, inclusief supplementen:
http://www.cs.bath.ac.uk/~jjb/ftp/CaliskanEtAl-authors-full.pdf
-
Artikel in Science hierover:
http://www.sciencemag.org/news/2017/04/even-artificial-intelligence-can-acquire-biases-against-race-and-gender
-
een video van een presentatie van een vd researchers over dit artikel:
https://www.youtube.com/watch?v=n7WKo_duKTM
-
code & data GLOVE:
http://nlp.stanford.edu/projects/glove/
-
-
onderzoekers:
-
- Aylin Caliskan-Islam
https://www.princeton.edu/~aylinc/
-
- Joanna J Bryson
http://www.cs.bath.ac.uk/~jjb/web/publications.html
-
- Arvind Narayanan
http://randomwalker.info/
-
-
https://github.com/clips/dutchembeddings
- word embeddings getraind op nederlandse teksten, door oa. Walter Daelemans
-
http://www.lrec-conf.org/proceedings/lrec2016/pdf/1026_Paper.pdf
overige / non-profit opties
Nederlandse machine learning / text mining bedrijven
-
http://www.xomnia.com/references/recruitment/
een ML toepassing binnen een sollicitatie proces, in opdracht van Randstad. Hebben ook voor politie gewerkt, persgroep en meer.
-
https://www.textkernel.com/company/about-textkernel/
spin-off van de Universiteit Tilburg, machine learning ingezet voor sollicitatie processen oa.
-
https://www.braincreators.com
(consultancy bedrijf)
-
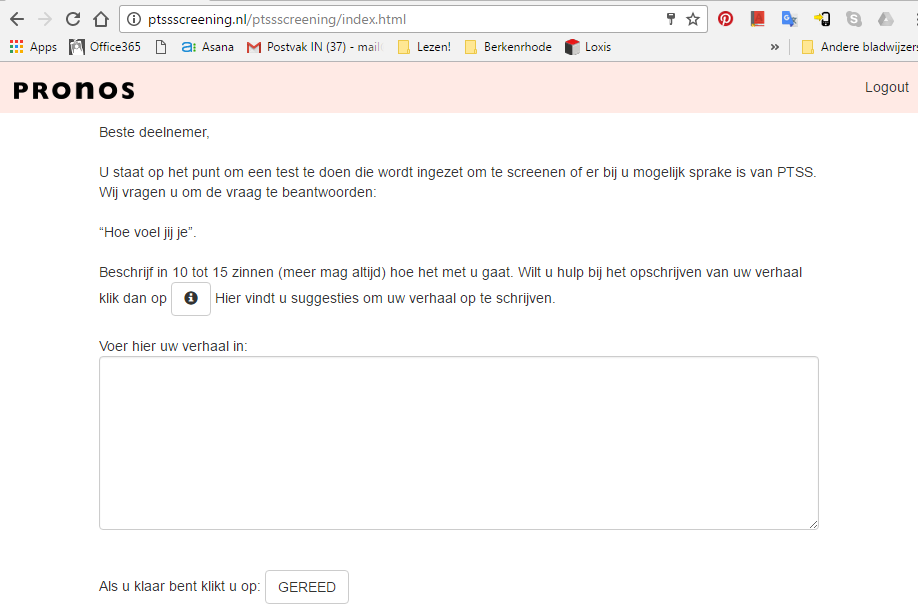
https://www.pronos.nl/
text mining voor het vaststellen van posttraumatische stressstoornis
-
"De PTSS Screener zorgt voor vroegtijdige herkenning van een posttraumatische stressstoornis. Zo wordt erger voorkomen. De PTSS Screener werkt met het gegeven dat mensen door hun woordkeus onbewust hun gezondheidstoestand blootgeven. De deelnemer maakt het ‘egodocument’, een tekst van een tekst van 10 tot 15 regels. De PTSS Screener analyseert deze tekst en zoekt naar signalen dat de deelnemer PTSS heeft. We noemen dit text mining. Voor elke deelnemer blijven twee opties over: er is zeer waarschijnlijk géén sprake van PTSS, of er is zeer waarschijnlijk sprake van PTSS. Die laatste groep moet worden onderzocht in het reguliere medische circuit opdat een definitieve diagnose kan worden gesteld."
https://www.pronos.nl/wp-content/uploads/2017/01/screener_screenshot.png
-
https://www.wcc-group.com/
WCC smart search and match, Rotterdam - identity matching / job matching
-
academische text mining tools
links
---
mogelijke opties in andere woorden:
Profilering aan de hand van persoonlijk geschreven tekst, zoals emails. Aan de hand van de volgende paramaters: leeftijd, geslacht, educatie niveau, interesses, etc. Een persoonlijke schrijfwijze is de bron van een data-gedreven profiel. Koppeling naar een dystopisch (nog) fictief scenario. Gebruikt voor targeted marketing, copyright breking, schrijf support.
Hoe kunnen we dit onderwerp constructief benaderen?
Perspectieven in tekst, verschillende gedeelde opvattingen die gedeeld worden door groepen. Information retreival? Classificatie task om verschillende groepen tekst te classificeren? Het Piek Vossen project is hier mee bezig, en in hun onderzoek gaan ze uit van meervoudige perspectieven in geschreven tekst door mensen. Haken hier onze interesses op in om naar de meervoudige perspectieven van de computer te kijken? Maar deze richting is heel taalkundig, en ook echt gericht op academisch onderzoek (op dit moment).
Interessant zou zijn om met een project te werken dat is toegespitst op een specifiek platform zoals bijv. Reddit. Hoe specifieker de context, hoe meer uitzonderingen of specifieke aanpassingen het systeem zou kunnen hebben om te functioneren.
Tekst kwaliteits analyse systemen die, bijvoorbeeld op Wikipedia, de gemeenschap ondersteunen bij het bewerken en verbeteren van artikelen. ML als achtergrondsproces in Wikipedia, waardoor het minder snel een algemener publiek aanspreekt.
---
constellaties van mogelijkheden:
enkel model
- context van specifiek model
- visualisatie van specifiek model
- fictief verhaal gebaseerd op specifiek model
meerdere modellen
- context van meerdere projecten
- draaien van getrainde modellen
* visualisatie van algemene technische NN elementen
*- fictieve vertaalslag
- een bestaand model
- een zelfgeschreven model
- algemene onderdelen
Brainstorm model
* Gijs: interesse voor model dat wordt gepresenteerd als werkend model door universiteit of bedrijven, en daar aanpassingen aan doen. Interesse voor modellen rondom politici, een link naar speeches of auteursherkenning/leeftijdsherkenning (profilering);
* Manetta: hoe kan ML systeem een nieuw inzicht brengen? leestool voor grote stapel boeken, topic modeling
Wikipedia gebruikt het om kwaliteit van artikel te verbeteren, model dat op positieve manier wordt ingezet
Gijs: weg van kritiek op ML en inzetten als poëtisch middel, al dan niet met functie
recommendation systeem van artikels/hoofdstukken/paragrafen...
eventueel een xmpp extensie?
* An:
Schrijvers dialoog. Het idee om machine learning te gebruiken om zelf anders te gaan schrijven. Bijv. auteursherkenning, op basis van bekende schrijvers is het model in staat om teksten te classificeren. Zoals bijvoorbeeld een spell-checker. Meer gericht op schrijven dan lezen. Een vorm om mee in dialoog te kunnen gaan. Een gesprekspartner die woorden suggereert om jou een richting op te sturen. Hierbij zijn gemakkelijke datasets voor te stellen, dmv een automatisch labeling proces, zodat je meteen aan een proces kan beginnen. Voorbeeld: 2 millioen zinnen per schrijver.
Een andere tak: Wanneer mogelijk graag totaal politiek: "wat is inclusief schrijven?" "wat is feministisch schrijven?" Als kritiek op patriarchisme. Voor mensen die bewust met taal om willen gaan, dat die iets aan het model hebben. De dataset wordt alweer een moeilijkere kwestie dan, we moeten dan op zoek naar auteurs met een bepaalde ideologische blik in hun schrijven. Ook omdat inclusiviteit meer een subjectief thema is.
Dunne lijn tussen geloven dat machine learning een betekenisvolle uitkomst kan geven, en de fascinatie voor de uitkomsten die gemaakt worden.
Een lijn tussen zien dat 'learning' het herkennen is van patronen in getelde woorden/features, en de wijze waarop deze methodes machine learning systemen laten 'werken'.
An: Bij auteursherkenning is the basis heel helder, schrijfwijze is direct gekoppeld aan de auteurs-categorie, waardoor de categorisatie een goed begrijpbaar proces is.
Wanneer een input tekst overeenkomt met een klasse binnen het model is het duidelijk dat de schrijfwijze op een manier overeenkomt, en dat dat misschien wel op overkoepelende gedachtegangen zou kunnen wijzen.
http://www.clips.uantwerpen.be/cgi-bin/stylenedemo.html
Manetta: hoe je kan leren van systemen, hoe ze keuzes makes
wanneer elementen worden toegevoegd, hoe beïnvloedt dat keuzes
op niveau van classifier, én ook op concept van 'dat werkt'
leren van houdingen die in systeem zitten
Een excercise de Style versie waarin teksten kunnen worden ge-skinned, in een bepaalde tekst kan worden getransformeerd.
zoals beelden bepaalde stijlen kunnen aannemen, geheugen van canonauteurs gebruiken voor je eigen povere Engels
http://genekogan.com/works/style-transfer/
- auteursherkenning: wat betekent het om in de klasse "Herman Brusselmans" te vallen?
- similarity search: wanneer zijn twee zinnen volledig overeenkomstig? Het onmogelijke aspect hiervan resoneert naar de onzekerheid van uitkomsten.
- machine translation:
- topic extraction (alternatieve lees interfaces)
constructief / reactief
constructief
- ML als zoek techniek, manier van kennis ordenen en alternatieve lees methodes ontwikkelen
- archief van Stedelijk Museum (SMTP)
- sociale media tijdslijnen
- bibliotheek (Texcavator & Koninklijke bibliotheek)
- historie van "democratie" (UvA CREATE) => concrete toepassing?
- iets à la Asibot
- ML als kwaliteits beheer
- wikipedia vandalisme bestrijding (ORES)
- ML om menselijke bias vast te stellen
- academische paper over machine learning & human bias
Andere constructieve elementen waar ik aan moet denken zijn:
-
- focussen op Nederlandse/Belgische machine learning projecten als alternatief om te spreken over de techniek, in plaats van een algemene machine learning wereld. En op deze manier kunnen we makkelijker in direct contact komen.
-
- het boek tweetalig maken
reactief (kritisch)
- ML in het publieke domein, en visualisaties als een manier om inzicht te geven op de rol van ML
- sollicitatie procedures (Randstad)
- aanbevelings algoritmes van advertenties
voorstellen
- focus op GLoVE word embeddings, met een referentie naar de paper over het aantonen van human bias in text
https://arxiv.org/abs/1608.07187
-
vector distances dmv. word embeddings (GLoVE), pre-trained met de Common Crawl training set
-
neurale netwerken
+ interview met academici over motivatie + toepassingen zoeken van word-embeddings in nederland/belgië + de pre-trainde GLoVE analyseren + Common Crawl dataset uitspitten (context)
+ complexe code visualiseren, en zo laten zien hoe human-bias herkend kan worden + zelf tests draaien met eigen onderwerpen (visualisatie)
+ fictief verhaal over herkennen van human bias (fictie)
- focus op Stedelijk Museum archief
-
topic clustering
-
klassiek machine learning (geloof ik)
+ het verhaal van ML in archiverings discourse, en specifiek van het museum (context)
+ met de code werken die gebruikt is voor het archief om zo verschillende leesmethodes te maken (visualisatie)
+ het onderzoek gebruiken als basis voor een fictief verhaal door het archief (fictie)
- focus op Wikimedia's ORES
-
classificatie taak
-
klassiek machine learning (geloof ik)
+ het verhaal achter ORES vertellen, overwegingen van definitie van vandalisme etc. (context)
+ met de code werken, en zo visualiseren hoe tekst classificatie in zijn werk gaat (visualisatie)
+ als basis gebruiken voor fictief verhaal over het weren van vandalisme en slechte kwaliteit van informatie (fictie)
voorbeeld van API output:
https://ores.wmflabs.org/scores/enwiki/draftquality/768416538
- focus op een schrijftool die een tekst kan herschrijven in verschillende auteur-stijlen
op basis van project Asibot/Giphart van Mike & co
Het idee is dat Giphart en de computer op elkaar reageren. De auteur tikt in een Word-achtig programma een zin, waarna de software met suggesties komt. Gevoed door duizenden boeken zou de kunstmatige intelligentie normaal gesproken met een nogal generiek geformuleerde zin komen. Om dit te voorkomen, krijgt de schrijver toegang tot een aantal verschillende stijlen die hij kan aanroepen.
Een eigen Giphart-knop bijvoorbeeld, op basis van alle Giphart-romans die zijn ingevoerd. Hij kan vervolgens ook gaan mixen: Giphart met sciencefictionauteur Isaac Asimov. Of een vleugje meer creativiteit.
voorbeelden van de Asibot:
https://www.mupload.nl/img/ogpyimm5axnre.jpg
-
+ (context) neurale netwerken op karakter basis, monitoring van de schrijver bijv. zinnen/opties die hij wel/niet kiest, context van de Volkskrant die niet geïnteresseerd is in techniek en CLiPS niet eens noemt, contact met schrijvers waarvan materiaal is gebruikt als trainingsdata
-
+ (visualisatie) werken met eigen data: gutenberg? common crawl? zelf verzamelde data?
-
+ (fictie) een boom zou kunnen een eerste aanzet geven aan bladeren en wortels voor realisatie van dagelijkse productie van suikers en mineralen, en vanuit verschillende bronnen komt een voorstel; of de boom kan specifiëren vanuit welke hoek (stijl) de voeding komt en beslist of die wel of niet past
- focus op model dat de metafoor van het bos aanhoudt:
https://arxiv.org/abs/1702.08835
pdf:
https://arxiv.org/pdf/1702.08835.pdf
software:
https://github.com/kingfengji/gcForest
In this paper, we propose gcForest, a decision tree ensemble approach with performance highly competitive to deep neural networks. In contrast to deep neural networks which require great effort in hyper-parameter tuning, gcForest is much easier to train. Actually, even when gcForest is applied to different data from different domains, excellent performance can be achieved by almost same settings of hyper-parameters. The training process of gcForest is efficient and scalable. In our experiments its training time running on a PC is comparable to that of deep neural networks running with GPU facilities, and the efficiency advantage may be more apparent because gcForest is naturally apt to parallel implementation. Furthermore, in contrast to deep neural networks which require large-scale training data, gcForest can work well even when there are only small-scale training data. Moreover, as a tree-based approach, gcForest should be easier for theoretical analysis than deep neural networks.
poetisch / beschouwend / observerend / artistiek / functioneel / bespiegelend / bekijken / signalerend / mediterend / reflecterend / activerend / loerend / bekijkend / bestuderend / een ontmoetend boek
-
artistiek beschouwend
-
artistiek bespiegelend
-
poëtisch beschouwend
-
meervoudig beschouwend
-
meervoudig observerend
-
bespiegelend observerend
-
bespiegelend reflecterend
contact email
Beste ...
Mijn naam is Manetta Berends, en mede namens An Mertens en Gijs de Heij schrijf ik deze mail om in contact te komen met machine learning projecten in het Nederlands taalgebied (Nederland/Vlaanderen). We combineren onze beroepspraktijken als kunstenaars, ontwerpers en schrijfster met een interesse in machine learning en natural language processing. We wonen en werken in Rotterdam (Manetta) en Brussel (An & Gijs) en werken op dit moment aan een artistiek onderzoeksproject met de steun van het Nederlandse Stimuleringsfonds
Creatieve Industrie
Digitale Cultuur.
In dat kader zijn we volop in de voorbereidingen van een artistiek bespiegelend boek, onder de werktitel Algorithmic Uncertainty, waarin we het maak- en uitvoeringsproces van een machine learning model vanuit verschillende perspectieven willen beschouwen en leesbaar maken. We willen dit doen door middel van interviews, visualisatie-experimenten en een fictief verhaal. Onze waarnemingen zullen specifiek gericht zijn op momenten van benadering en compromis, die we zowel binnen de software zullen zoeken als ook in de mechanismes die rondom een model ontstaan, zoals bijvoorbeeld methodes om trainingsdata te maken. We schrijven alledrie ook zelf code, en willen ons heel bewust richten op het leesbaar maken van het software-proces. Hierdoor zijn we met name geïnteresseerd om een bestaand en getraind model te deconstrueren, om dat vervolgens centraal te zetten in de verschillende software experimenten.
<<< hier over specifiek project >>>
We zouden graag meer horen over het project, welke software er is gebruikt, hoe de trainingsdata is verkregen, waar het project door beperkt werd, waar de resultaten terecht komen, etc. Zouden jullie interesse, tijd en energie hebben om eens met ons af te spreken?
<<<
CREATE (Manetta)
-
<<<Tijdens het zoeken naar een machine learning model kwamen we terecht bij SMTP, het Stedelijk Museum Textmining Project. Het project sprak ons erg aan, zowel vanuit een cultureel-historisch
perspectief
als ook vanuit de gebruikte 'community detection' en 'time based topic modeling' technieken.
-
Onze artistieke praktijk is eveneens ingebed in een transdiscipl
in
aire context met institutionele partners (archieven, technologie, design, literatuur....).
Daarom
zijn
we
benieuwd naar de ervaringen van de
verschillende partners
die genoemd worden in het SMTP artikel.
We zouden graag
meer horen over het project, welke software er is gebruikt, hoe de trainingsdata is verkregen, waar het project door beperkt werd, waar de resultaten terecht komen, etc. Of misschien zijn er nog verwante projecten binnen CREATE die aansluiten op onze vragen? Zouden jullie
interesse,
tijd en energie
hebben om eens met ons af te spreken? >>>
-
-
Claartje Rasterhoff C.Rasterhoff@uva.nl
-
Julia Noordegraaf J.J.Noordegraaf@uva.nl
-
http://www.create.humanities.uva.nl/text-mining/
-
http://www.dhbenelux.org/wp-content/uploads/2016/05/91_StedelijkMuseumTextMiningProject_FinalAbstract_DHBenelux2016_short.pdf
-
Stedelijk Museum Amsterdam : Margriet Schavemaker theorie/hedendaagse kunst
http://www.margrietschavemaker.nl
-
JC Scholtes & ZyLAB:
https://www.maastrichtuniversity.nl/nl/j.scholtes
-
https://zylab.com/company/
-
Jeroen Smeets, Maastricht University, smeetsjeroen@hotmail.com
-
-
Relation Networks and Community Detection, op basis van named entity extraction (als namen voorkomen in hetzelfde document staan ze in relatie met elkaar), ruwe manier
-
Time based Topic Modeling, gebaseerd op een Non-Negative Matrix Factorization (NMF), dit wordt uitgedrukt in "topic strength"
-
Ruw en grof onderzoek, geven ze ook zelf toe. Het project was voor de CREATE groep een onderzoek naar de waarde van computer analyses op historische archieven.
-
combinatie van 2 technieken, interessant owv smaenwerking tussen 2 ML onderzoekers, iemand van Museum en onderzoeker Geesteswetenschappen
-
inkijk in onderzoek graag!
DJOERD HIEMSTRA
(Gijs)
PIEK VOSSEN
-
Het project .... spreekt ons erg aan, met name omdat het vertrekt vanuit een zoektocht naar perspectieven in menselijke taal.
ORES
(An)
KB (Manetta)
-
De oproep is specifiek gericht op PHD studenten.
https://www.kb.nl/organisatie/vacatures-en-stages/researcher-in-residence-2018
-
De KB gebruikt IR, NLP en ML voor hun digitale content. Een specifieke afdeling is deze:
https://www.kb.nl/organisatie/onderzoek-expertise/verrijking-van-digitale-content
-
Kunnen we een onderzoeker vinden die met data van de KB heeft gewerkt in een concreet machine learning project?
-
-
<<< Via de website van de Koninklijke Bibliotheek kwamen we het DBNL Ngram viewer ... >>>
-
- werkwijze, historische tekst analyse met ML?
-
- aanspreekpunt bij de KB om in contact te komen met verwante ML projecten
-
Frame generator (
http://lab.kb.nl/tool/frame-generator
) tool die de context van begrippen uit een dataset kan extraheren (?) doet dit door middel van topic modeling (met behulp van externe libraries) en co-ocurence patterns.
-
Keyword Generatorm extraheert veelzeggende keywords uit een data set, gebasseerd op topic-models of tf-idf (term-frequency inverse-document-frequency)
-
Genre Classifier (
http://lab.kb.nl/tool/genre-classifier
) klassificeert welk 'type' een tekst is; nieuwsbericht, reportage, colum, recensie, ... . Met behulp van een eerder gemaakte dataset werd een svm-classifier getraind, deze classifier heeft een precisie van 65%.
-
Op jullie website kwam ik verschillende projecten tegen die gebruik maken van machine learning, bijvoorbeeld the frame generator of the historische ngram viewer. We zijn benieuwd hoe jullie machine-learning inzetten in het onderzoek maar ook naar de overwegingen in het keuze-proces voor bepaalde technieken. Daarbij zijn we met name geïnterresseerd in de momenten van onzekerheid binnen het algoritme.
-
-
Hoe doorgronden jullie de technieken die jullie inzetten
>>>
in latere email:
- gepubliceerde code
- eventueel artikelen
overlappende thema's
Mike
KB
ORES
Djoerd Hiemstra
-
samenwerking bot/mens, dit framen als concurrentie
-
proces van de modellen, en de problemen die boven komen bij het maken trainingsdata
{kind=link}